不均衡データの学習 ~imblanced-learnを例に~
ちゃお・・・† まいおり・・・†
不均衡データとは?
不均衡データとはクラスに属するサンプルサイズに偏りがある不均衡なデータのことです。 例えば、ネット広告のCTR (Click Through Rate; クリック率) のデータは正例 (クリックした数) が少なく、負例 (クリックしなかったケース) がほとんどです。
そこでなんとか不均衡データを均衡にしていこうという試みがあります。対処法は大きく分けて2つあります。algorithm-level approaches (正例を誤答したときにペナルティを重くする方法) とdata-level approaches (正例と負例のサンプル数を調整する方法) です。この記事では後者について扱います。 以前に不均衡データに強いと謳っていたNegationNaiveBayesやその仲間について紹介しましたが、今回はimblanced-learnで採用されている手法を紹介していきます。
※結果的にほとんどimblanced-learnのドキュメントを日本語訳しただけの記事になってしまったので、imblanced-learn知ってるよ!って方はお手数ですが回れ右してください・・・†
Oversampling
Over samplingとはサンプルが少ない少数派クラスのサンプルを増やして均衡にしていくことです。
Naive random over-sampling (RandomOverSampler)
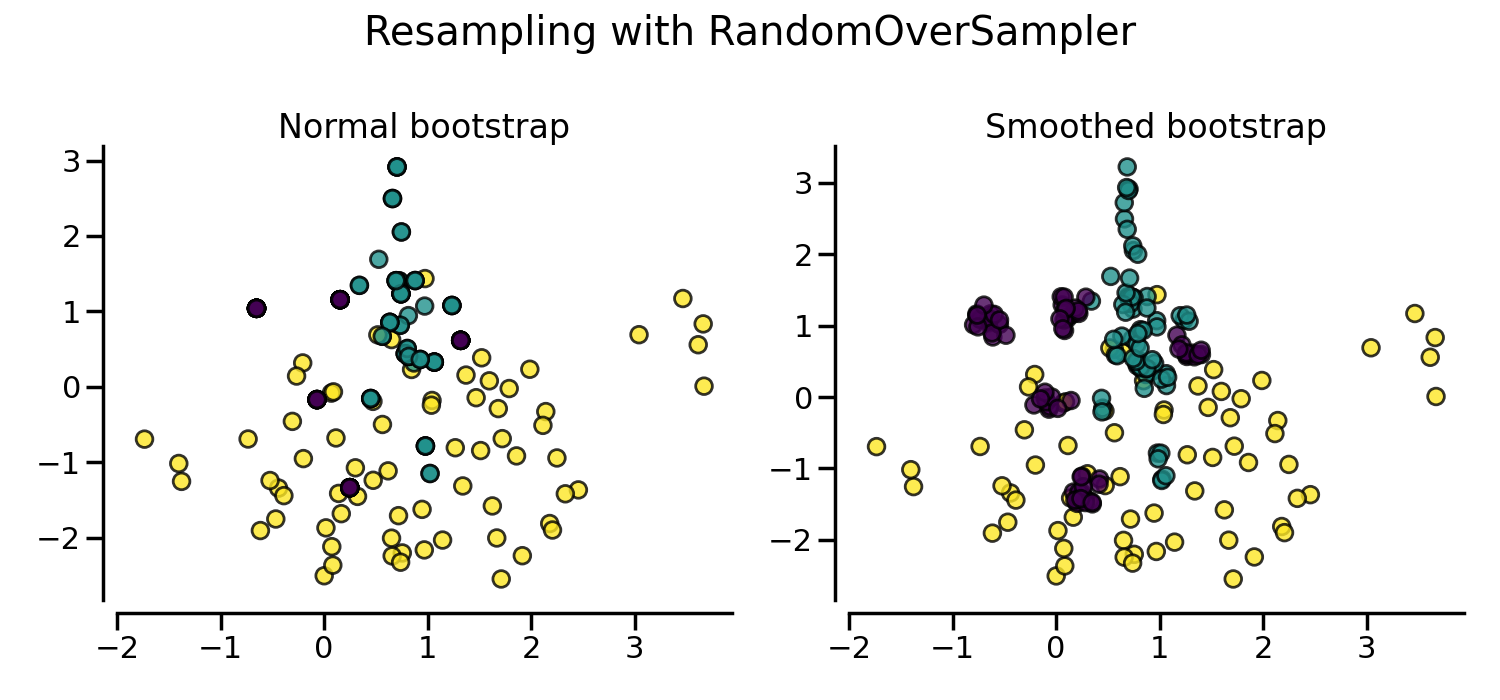
この問題を解決する1つの方法は、サンプルの少ないクラスで新しいサンプルを生成することです。 最も単純な手法は、利用可能なサンプルをランダムにサンプリングして新しいサンプルを生成することです。ただし、それだと過学習を引き起こしやすいことがあるので注意です。
サンプルの繰り返しが問題になる場合、shrinkage パラメータで平滑化されたブートストラップを作成することができます。ただし、元データを数値化する必要があります。shrinkage パラメータは、新しく生成されるサンプルの分散を制御します。平滑化されたブートストラップを用いると、新しいサンプルはもう重なりません。この平滑化ブートストラップの生成方法は、Random Over-Sampling Examples (ROSE) 論文 とも呼ばれます。
SMOTE and ADASYN
置換を伴う無作為抽出とは別に、(i) Synthetic Minority Oversampling Technique (SMOTE) と (ii) Adaptive Synthetic (ADASYN) サンプリング法といった2つの一般的な手法があります。
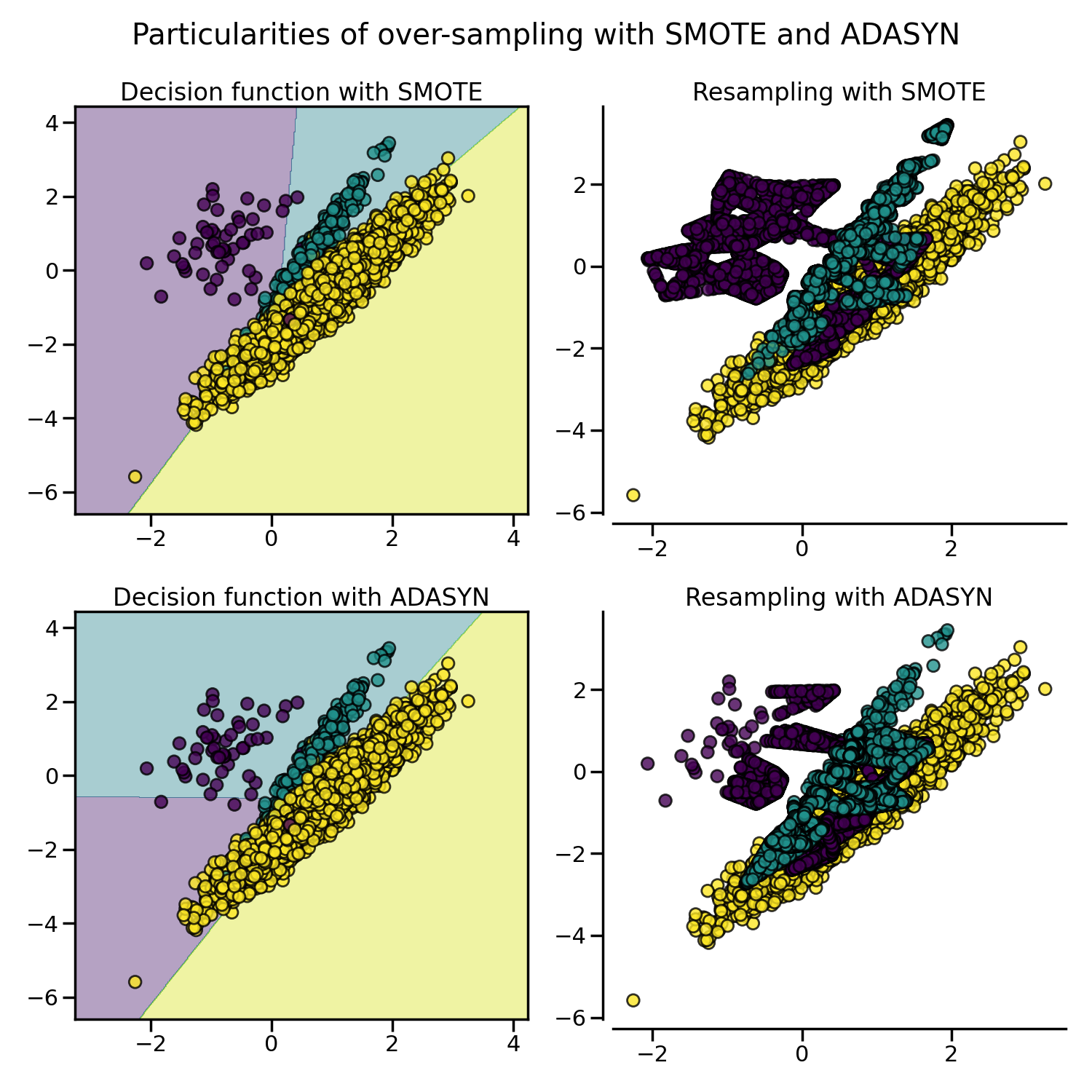
前述のRandomOverSamplerは少数派クラスの元のサンプルの一部を複製することによってオーバーサンプリングしますが、SMOTEとADASYNは補間によって新しいサンプルを生成します。 しかし、新しい合成サンプルを補間/生成するために使用されるサンプルは異なります。 ADASYNは、k-NN (k-nearest neighbor) 分類器を使用して間違って分類された元のサンプルの隣にサンプルを生成することに焦点を当てていますが、SMOTEのベーシックな実装では学習中に検出される決定関数はアルゴリズム間で異なります。
SMOTEはinlierとoutlier (外れ値) を接続することがありますが、ADASYNはどちらの場合も準最適な決定機能につながる外れ値のみに焦点を当てることがあります。 これに関して、SMOTEはサンプルを生成するための3つの追加オプションを提供しています。 これらの方法は、最適な決定関数の境界付近のサンプルに焦点を合わせ、最近傍クラスの反対方向にサンプルを生成します。
SMOTEとADASYNは新しいサンプルを生成するのに同じアルゴリズムを使います。を考えるとき、kNNによって新しいサンプル
は生成されます。これらの最近傍
が選ばれ、サンプルが以下のように生成されます。
各SMOTEとADASYNは、新しいサンプルを生成する前にサンプル$x_i$を選択することによってお互いに異なります。
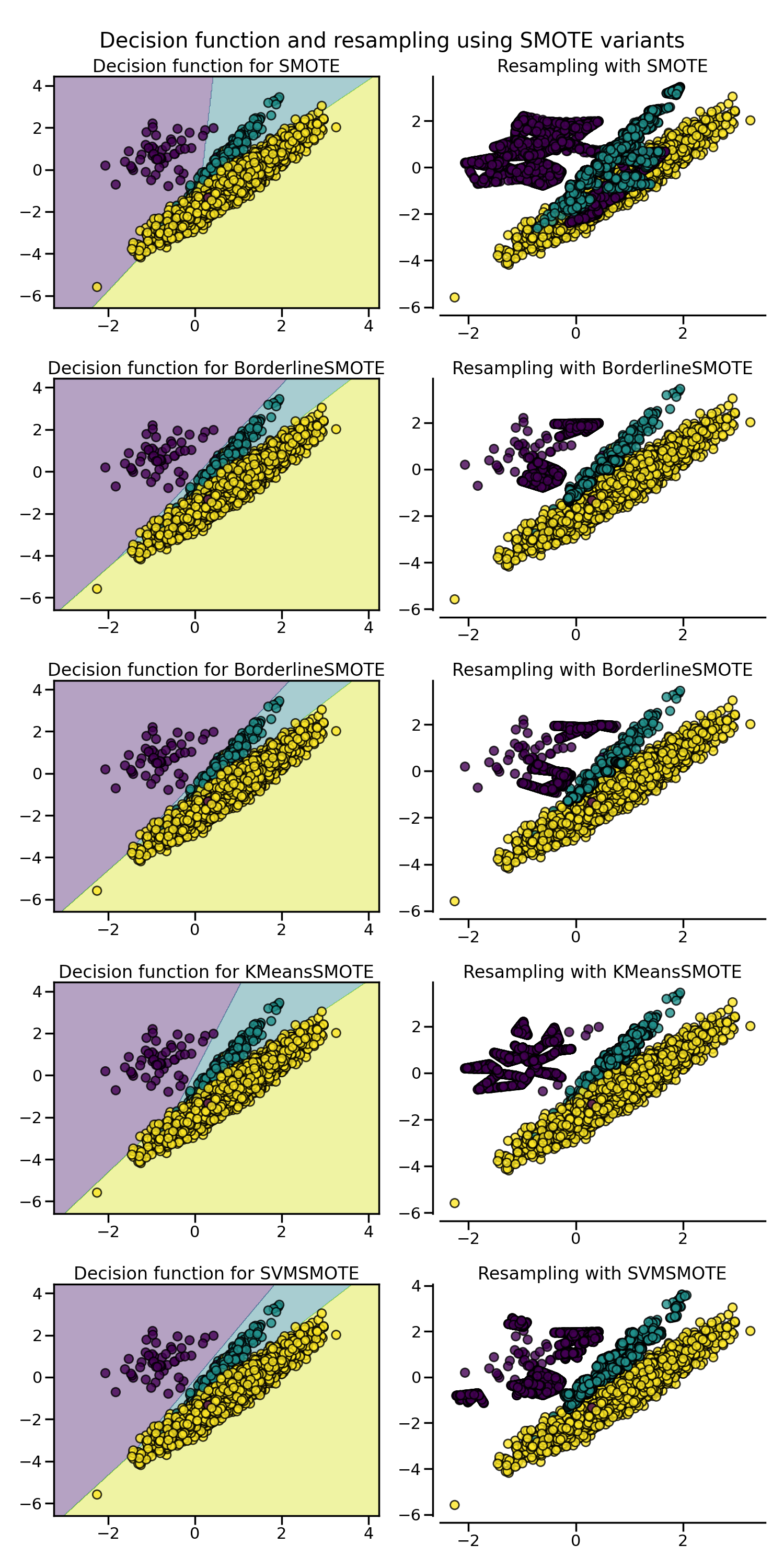
通常のSMOTEアルゴリズム
ルールを課すことなく、利用可能なすべてのをランダムに取得します。
Borderline SMOTE
各サンプルを(i)ノイズ (全ての最近傍が
のものとは異なるクラスである) 、(ii) 全ての最近傍は、
とは異なるクラスからのものである、または (iii) 安全である (全ての最近傍が
と同じクラスからのものである) Borderline-1 SMOTEでは、
はサンプル
と異なるクラスに属しますが、Borderline-2 SMOTEは
を考慮します。
SVM SMOTE
SVM (Support Vector Machine) 分類器を使用してサポートベクトルを見つけ、それを考慮したサンプルを生成します。 SVM分類器のCパラメータは、より多くのまたはより少ないサポートベクトルを選択することを可能にします。
ADASYN
ADASYNは通常のSMOTEと同様に動作します。しかし、各に対して生成されるサンプルの数は、所与の近傍における$x_i$と同じクラスにないサンプルの数に比例します。したがって、最近傍ルールが尊重されない領域では、より多くのサンプルが生成されます。
Under sampling
Under samplingとは多数派のクラス (majority class) のサンプルを減らして均衡にしていくことです。 Random under samplingでは有益なデータを削除してしまう可能性があります。一方で、クラスターベースの手法なら各クラスがdistinctなデータ群となるため、一部の有益なデータを消す事はありません。
Controlled under-sampling techniques
RandomUnderSamplerは、対象となるクラスのデータのサブセットをランダムに選択することで、データのバランスを取るための高速で簡単な方法です。
imbalanced-learn の RandomUnderSampler では、replacement を True に設定することでブートストラップを行うことができます。マルチクラスでのリサンプリングは,対象となる各クラスを独立に考慮することで行われます。
NearMiss
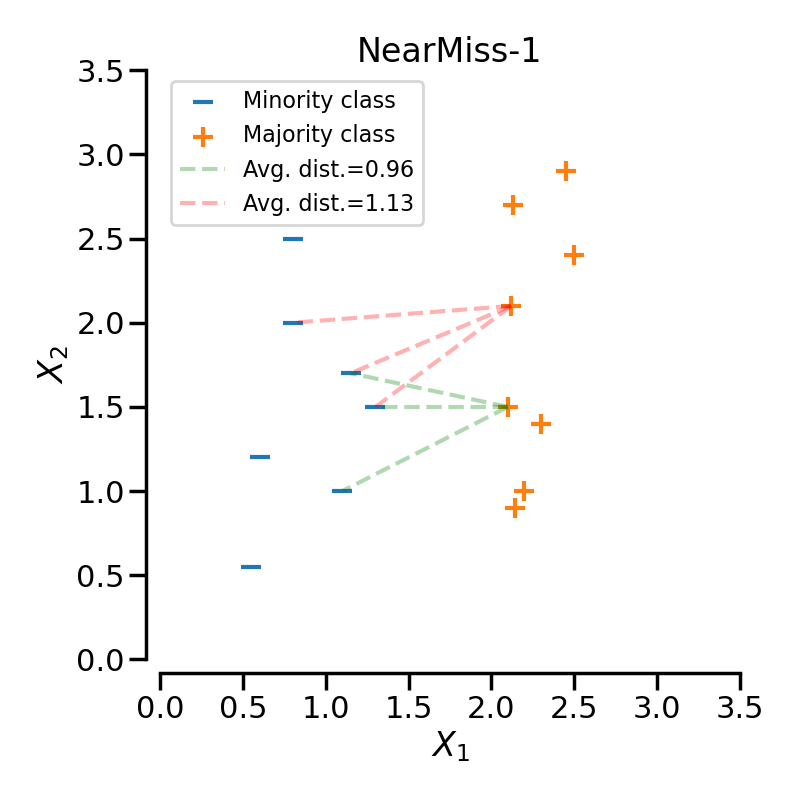
NearMiss-1では、少数派クラスの最も近いサンプルとの距離の平均が最も小さくなる多数派クラスのサンプルを選択します。
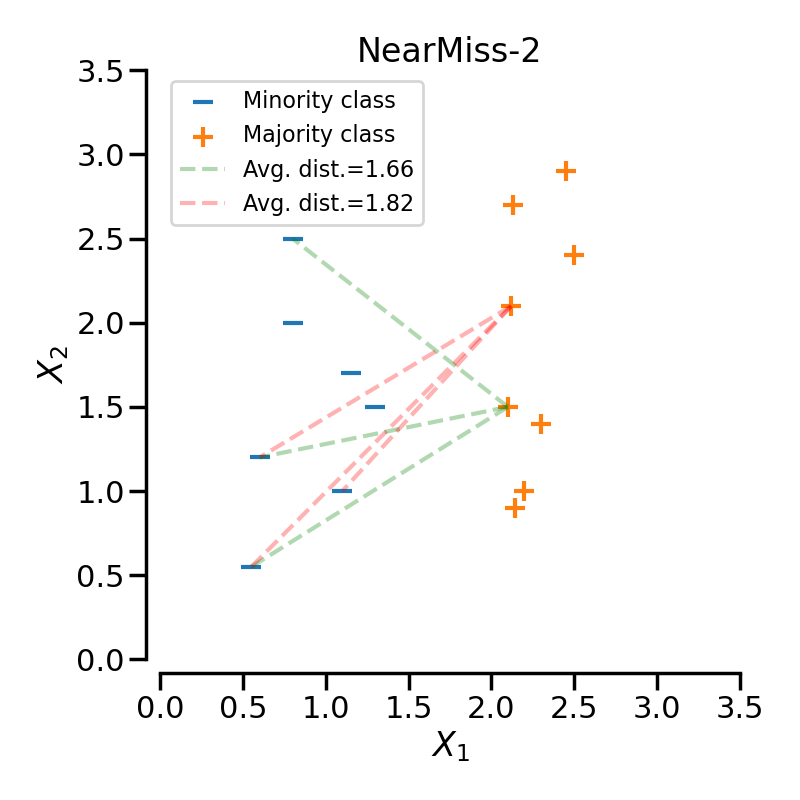
NearMiss-2は、少数派クラスの最も遠いN個のサンプルとの平均距離が最も小さい多数派クラスのサンプルを選択します。
NearMiss-3は2ステップのアルゴリズムです。まず、各少数派クラスのサンプルについて、そのM個の最接近傍を保持します。次に、N個の最近傍との平均距離が最大となる多数派クラスのサンプルを選択します。
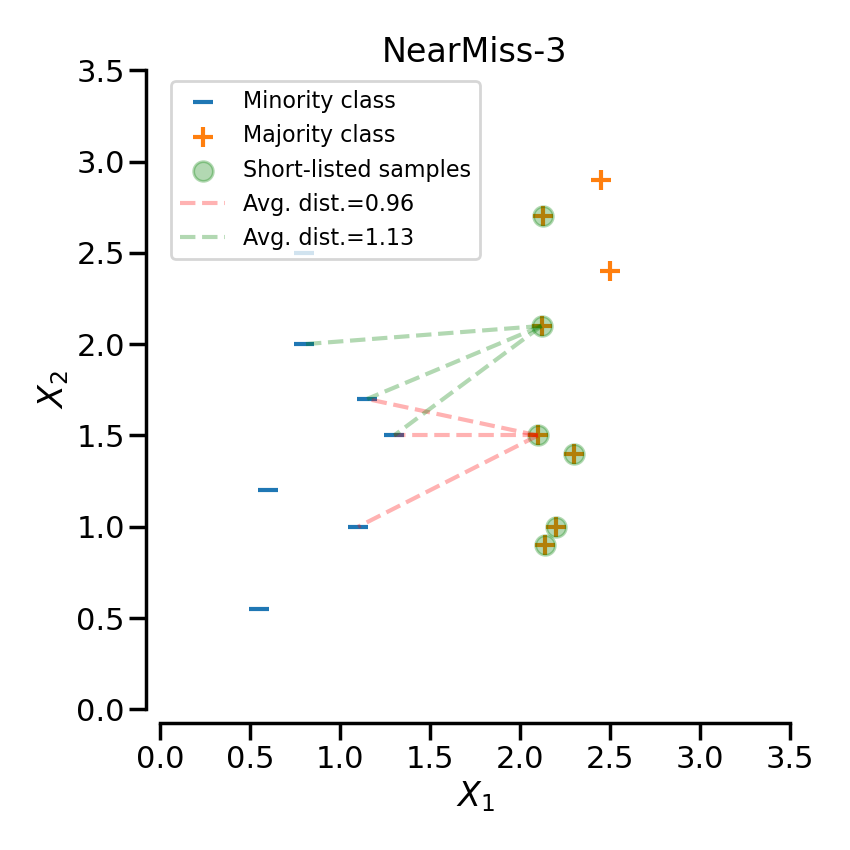
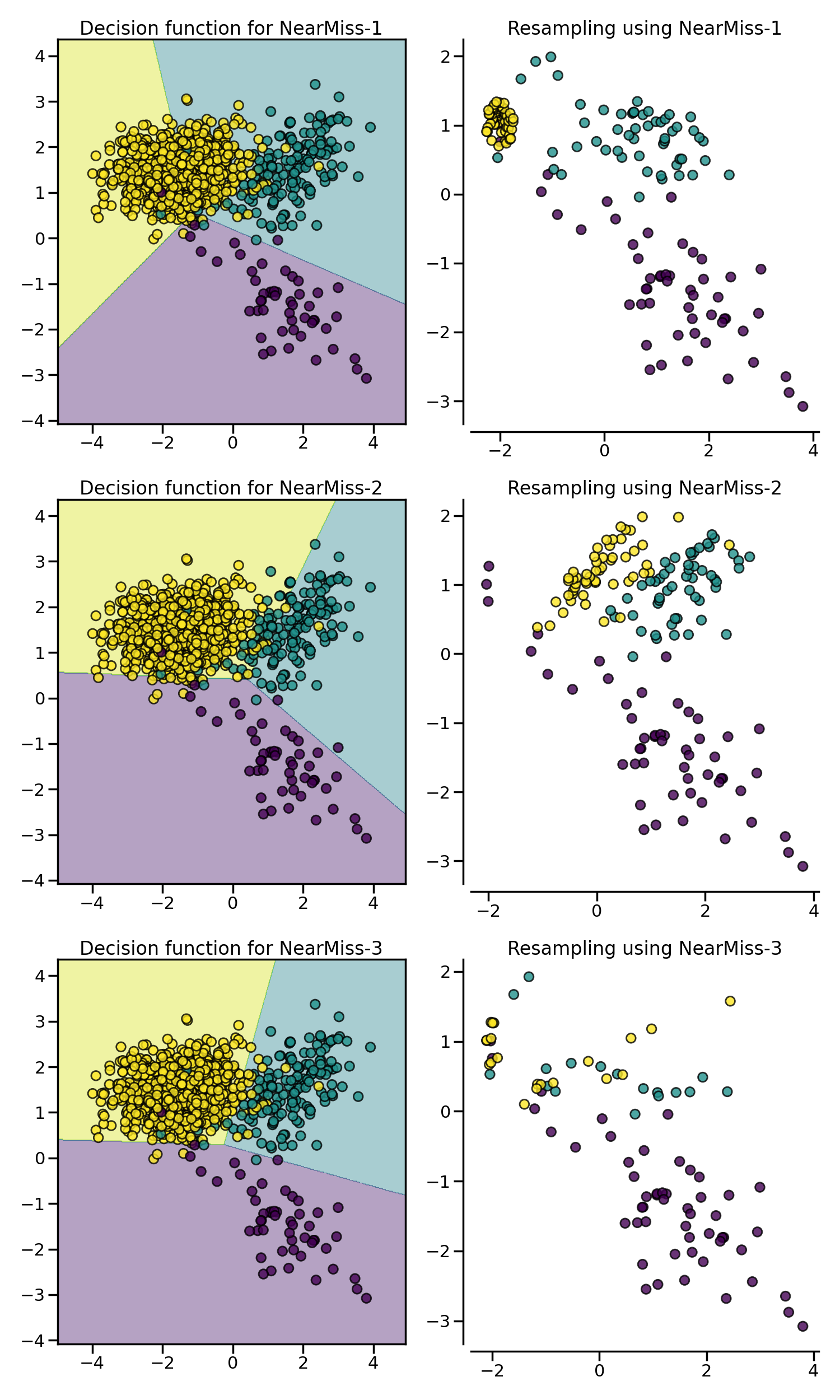
次の例では、異なるNearMissのバリエーションが、toy exampleに適用されています。それぞれのケースで得られる決定関数が異なっていることがわかります。
特定のクラスをアンダーサンプリングする場合、NearMiss-1はノイズの存在によって変化することがあります。実際、下の図の黄色いクラスのように、対象となるクラスのサンプルがこれらのサンプルの周囲で選択されることが暗示されます。しかし、通常は境界線に隣接するサンプルが選択されることになります。NearMiss-2は、最も近いサンプルに注目するのではなく、最も遠いサンプルに注目するため、このような効果はありません。また、ノイズの存在により、主にマージナルな外れ値が存在する場合にサンプリングが変化することが想像できます。NearMiss-3は、第一段階のサンプル選択により、ノイズの影響を受けにくいバージョンであると思われます。
Cleaning under-sampling techniques
クリーニングアンダーサンプリング技術では、各クラスのサンプル数を指定することができません。各アルゴリズムは、データセットをクリーニングするヒューリスティックを実装しています。
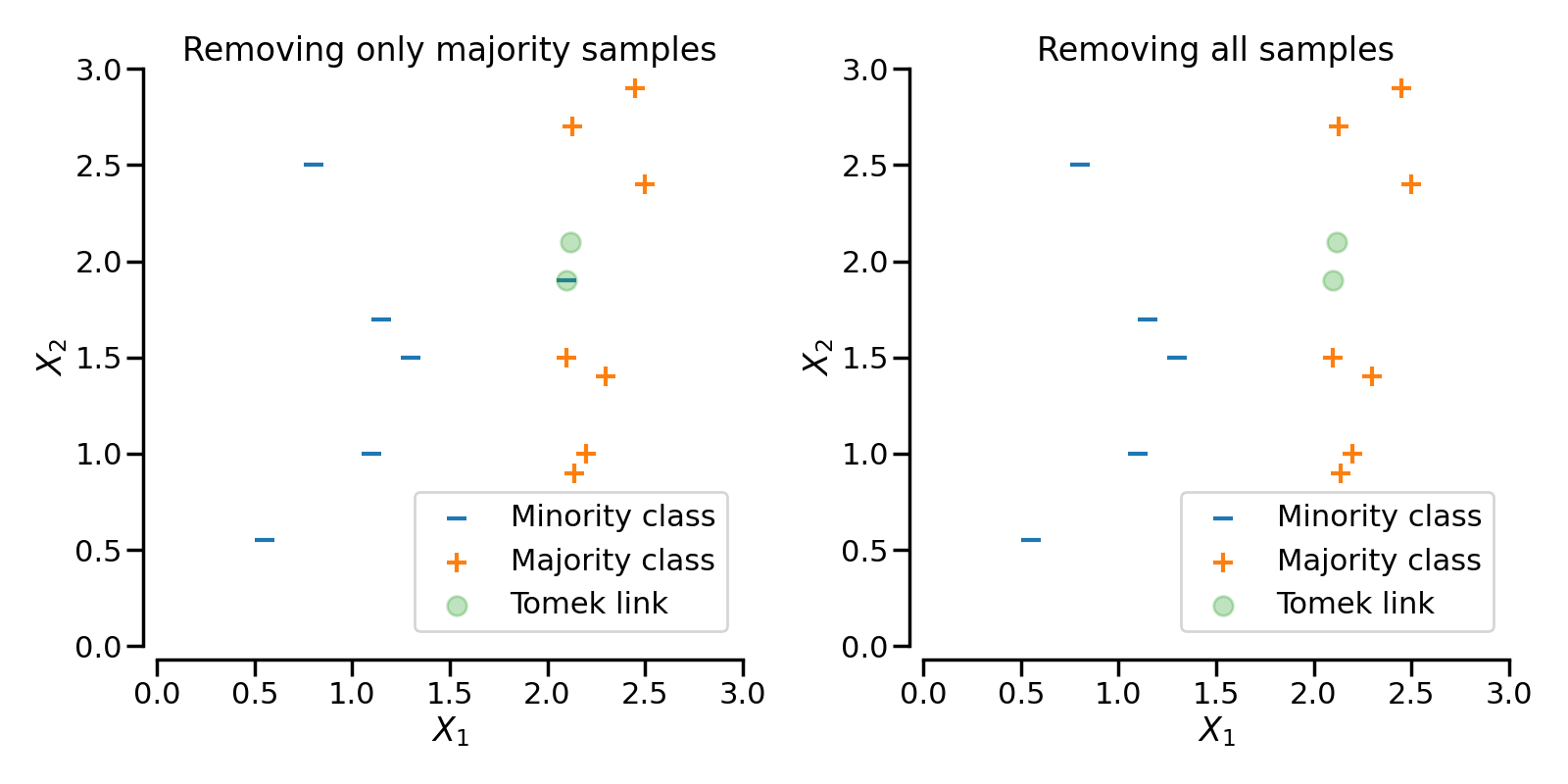
Tomek’s links
TomekLinks は、いわゆるTomek's links を検出します。異なるクラスと
の2つのサンプル間のTomekのリンクは、任意のサンプル
に対して次のように定義されます。
and
ここで、d(.)は2つのサンプル間の距離である。言い換えれば、2つのサンプルが互いに最も近い場合、Tomekのリンクが存在することになります。下図では、注目するサンプルを緑色でハイライトすることで、Tomek's links を表現しています。
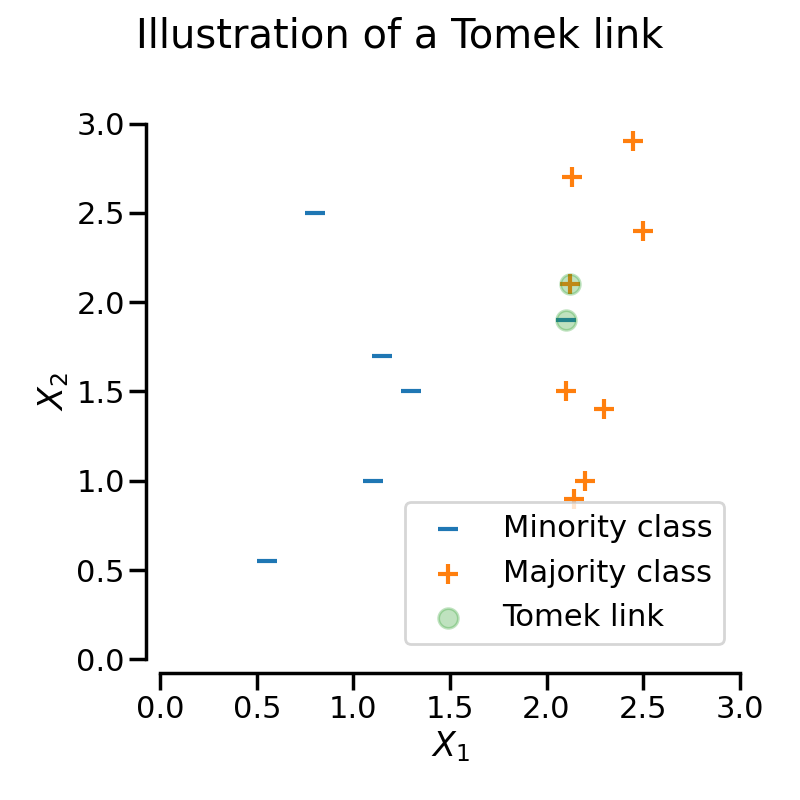
パラメータ sampling_strategy は、リンクのどのサンプルを削除するかを制御します。例えば、デフォルト (sampling_strategy='auto') では、多数派のクラスのサンプルが削除されます。sampling_strategyを'all'に設定することで、多数派クラスと少数派クラスの両方のサンプルを削除することができます。図にこの挙動を示します。
最近傍を用いてデータセットを編集
EditedNearestNeighboursは、最近傍アルゴリズムが適用され、近傍と「十分に」一致しないサンプルを削除することでデータセットを「編集」します 論文。アンダーサンプリングされるクラスの各サンプルについて、最近傍が計算され、選択基準が満たされない場合、そのサンプルは削除されます:
>>> sorted(Counter(y).items()) [(0, 64), (1, 262), (2, 4674)] >>> from imblearn.under_sampling import EditedNearestNeighbours >>> enn = EditedNearestNeighbours() >>> X_resampled, y_resampled = enn.fit_resample(X, y) >>> print(sorted(Counter(y_resampled).items())) [(0, 64), (1, 213), (2, 4568)]
現在 (2023/04/13)、2つの選択基準が利用可能です。 (i)過半数 (kind_sel='mode') または(ii)すべて (kind_sel='all') の最近傍が、検査したサンプルと同じクラスに属していないとデータセットに残すことはできません。したがって、kind_sel='all'はkind_sel='mode'よりも保守的になり、前者の戦略では後者の戦略よりも多くのサンプルが除外されることを意味します:
>>> enn = EditedNearestNeighbours(kind_sel="all") >>> X_resampled, y_resampled = enn.fit_resample(X, y) >>> print(sorted(Counter(y_resampled).items())) [(0, 64), (1, 213), (2, 4568)] >>> enn = EditedNearestNeighbours(kind_sel="mode") >>> X_resampled, y_resampled = enn.fit_resample(X, y) >>> print(sorted(Counter(y_resampled).items())) [(0, 64), (1, 234), (2, 4666)]
n_neighborsパラメータは、scikit-learnのKNeighborsMixinをサブクラス化した分類器に、最近傍を見つけ、与えられたサンプルを保持するかどうかの決定をさせることができます。
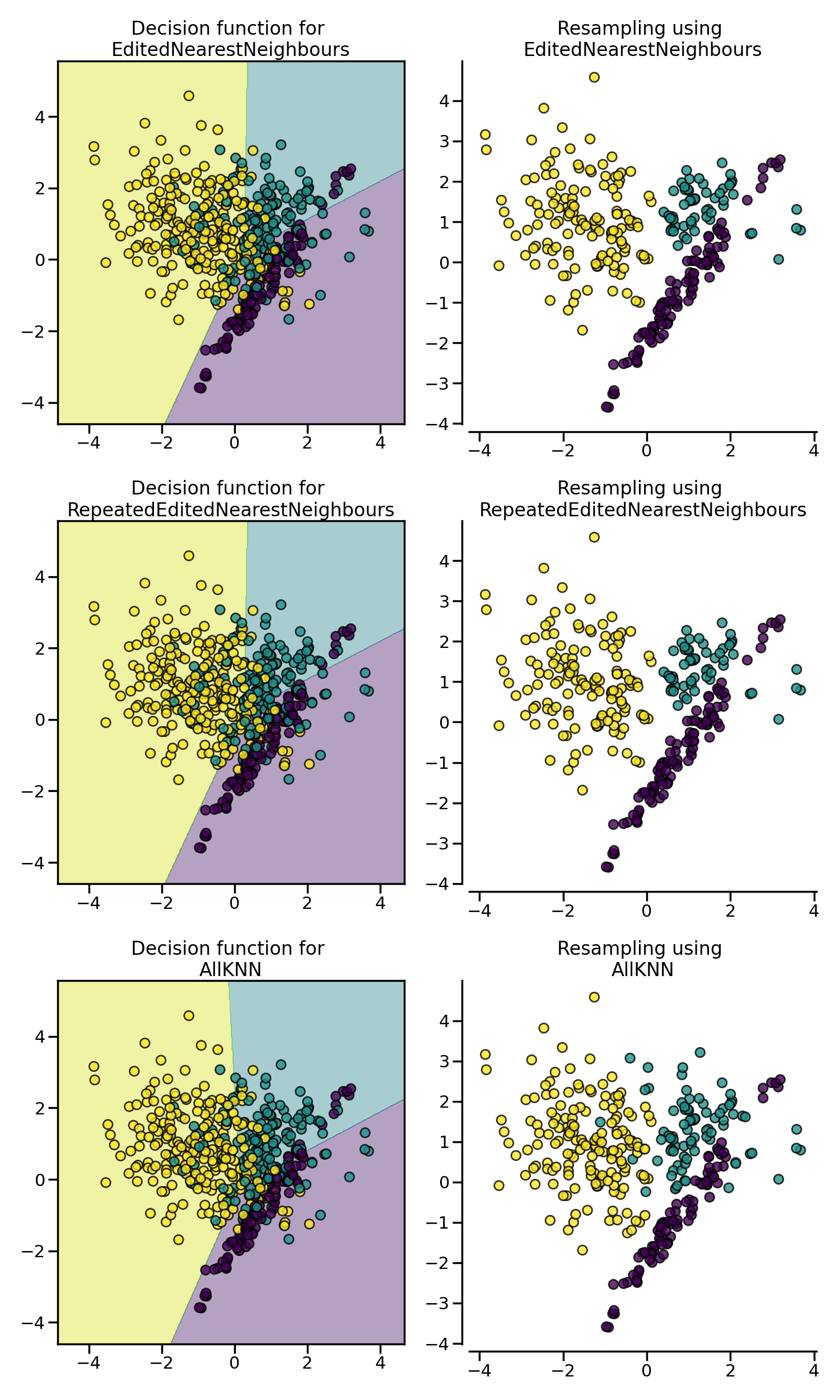
RepeatedEditedNearestNeighboursは、アルゴリズムを複数回繰り返すことでEditedNearestNeighboursを拡張しています 論文。一般に、アルゴリズムを繰り返すと、より多くのデータが削除されます。
>>> from imblearn.under_sampling import RepeatedEditedNearestNeighbours >>> renn = RepeatedEditedNearestNeighbours() >>> X_resampled, y_resampled = renn.fit_resample(X, y) >>> print(sorted(Counter(y_resampled).items())) [(0, 64), (1, 208), (2, 4551)]
AllKNNは先ほどのRepeatedEditedNearestNeighboursとは異なり、内部最近傍アルゴリズムの近傍数が各反復で増加します 論文:
>>> from imblearn.under_sampling import AllKNN >>> allknn = AllKNN() >>> X_resampled, y_resampled = allknn.fit_resample(X, y) >>> print(sorted(Counter(y_resampled).items())) [(0, 64), (1, 220), (2, 4601)]
下の例では、3つのアルゴリズムが、クラスの境界に隣接するノイズの多いサンプルをクリーニングすることで、同様の効果を発揮していることがわかります。
Combination of over- and under-sampling
オーバーサンプリングとアンダーサンプリングを組み合わせた手法です。
SMOTEENN
SMOTEとEdited Nearest Neighboursを組み合わせてover- and under-samplingします。
SMOTETomek
SMOTEとTomek linksを組み合わせてover- and under-samplingします。